

Introducing SQLCoder
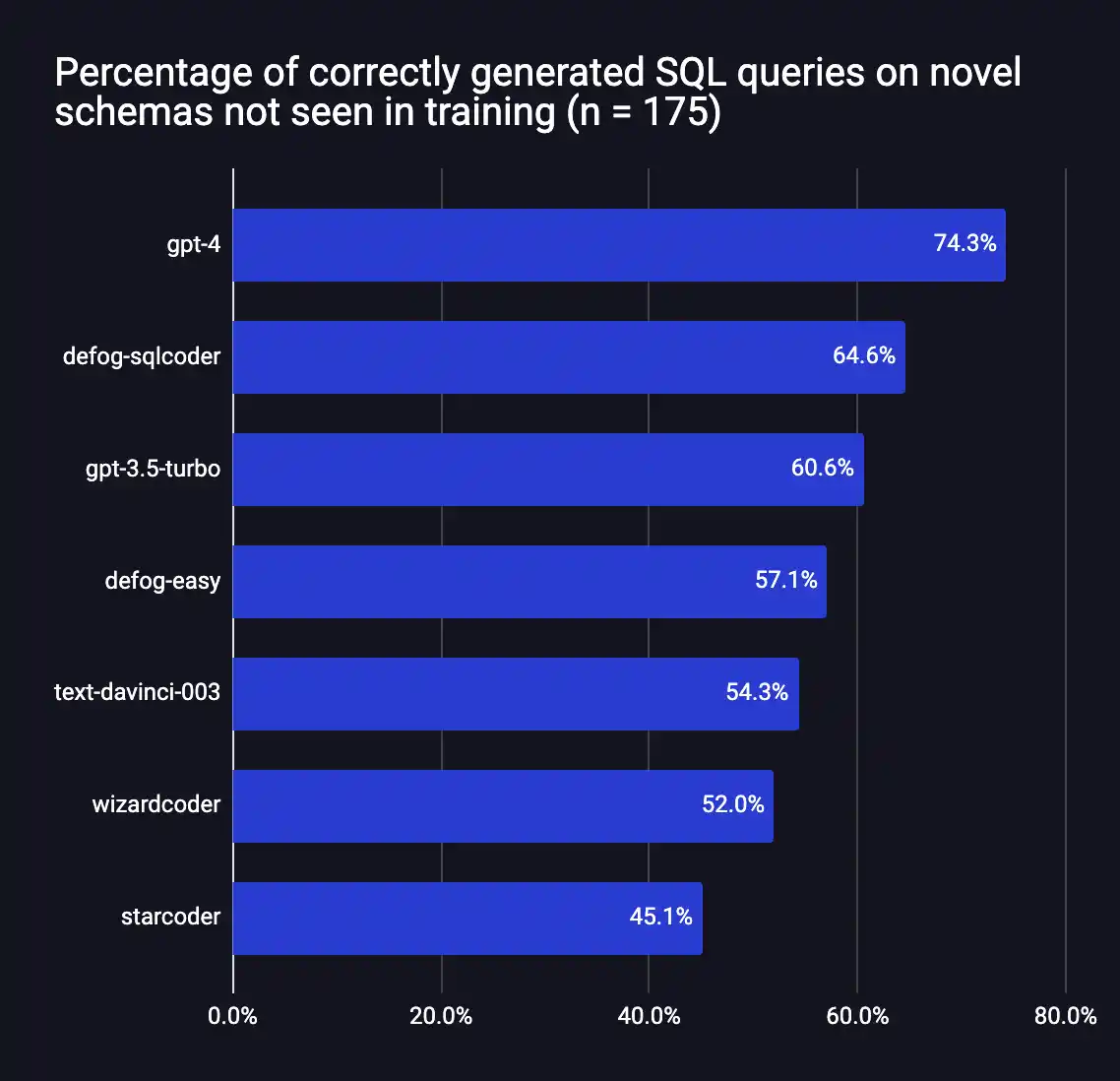
We are thrilled to open source Defog SQLCoder – a state-of-the-art LLM for converting natural language questions to SQL queries. SQLCoder significantly outperforms all major open-source models and slightly outperforms gpt-3.5-turbo and text-davinci-003 (models that are 10 times its size) on our open-source evaluation framework.
You can explore SQLCoder in our interactive demo at https://defog.ai/sqlcoder-demo
SQLCoder is a 15B parameter LLM, and a fine-tuned implementation of StarCoder. SQLCoder has been fine-tuned on hand-crafted SQL queries in increasing orders of difficulty. When fine-tuned on an individual database schema, it matches or outperforms GPT-4 performance.
You can find our Github repo here, and our model weights on Huggingface here. You can also use our interactive demo here to explore our model in the browser.
Motivation
In the last 3 months, we have deployed SQLCoder with enterprise customers in healthcare, finance, and government. These customers often have sensitive data that they do not want going out of their servers, and using self-hosted models has been the only way for them while using LLMs.
We were able to build a SOTA model that was competitive with closed source models. We did this while standing on the shoulders of giants like StarCoder, and open-sourcing the model weights is our attempt at giving back to the community.
Approach
Dataset Creation
We created a hand-curated dataset of prompt-completion pairs focused on text-to-SQL tasks. This dataset was created from 10 different schemas, and with questions of varying levels of difficulty. Additionally, we also created an evaluation dataset of 175 questions from 7 new schemas that were not a part of the 10 schemas in our training data.
We made sure that we selected complex schemas with 4-20 tables in both our training and evaluation datasets. This is because schemas with 1 or 2 tables tend to only result in simple, straightforward queries due to limited relations.
Question Classification
Once the dataset was created, we classified each question in the dataset into “easy”, “medium”, “hard”, and “extra-hard” categories. This classification was done by adapting the rubric utilized by the Spider dataset to gauge SQL hardness.
Finally, we divided the dataset into two distinct subparts – one with easy and medium questions, and the other with hard and extra-hard questions.
Fine-tuning
We fine-tuned the model in two stages. First, we fine-tuned the base StarCoder model on just our easy and medium questions. Then, we fine-tuned the resulting model (codenamed defog-easy) on hard and extra hard questions to get SQLcoder.
Evaluation
We evaluated our model on a custom dataset we created. Evaluating the “correctness” of SQL queries is difficult. We considered using GPT-4 as a “judge”, but ran into multiple issues with that. We also realized that two different SQL queries can both be "correct". For the question “who are the 10 most recent users from Toronto”, both of the following are correct in their own ways:
-- query 1 SELECT userid, username, created_at from users where city='Toronto' order by created_at DESC LIMIT 10; -- query 2 SELECT userid, firstname || ' ' || lastname, created_at from users where city='Toronto' order by created_at DESC LIMIT 10;
With this in mind, we had to build a custom framework to evaluate query correctness. You can read more about the framework here. In addition to open-sourcing our model weights, we have also open-sourced our evaluation framework and evaluation dataset.
Results
Defog SQLCoder outperforms all major models except GPT-4 on our evaluation framework. In particular, it outperforms gpt-3.5-turbo and text-davinci-003, which are models more than 10x its size.
These results are for generic SQL databases, and do not reflect SQLCoder’s performance on individual database schemas. When fine-tuned on individual database schemas, SQLCoder has the same or better performance as OpenAI’s GPT-4, with lower latency (on an A100 80GB).
Future direction
We will make the following updates to Defog in the coming weeks:
Explore the model
You can explore our model at https://defog.ai/sqlcoder-demo
About the authors
Rishabh Srivastava is a co-founder of Defog. Before starting Defog, he founded Loki.ai – serving more than 5 billion API requests for Asian enterprises.
Wendy Aw is a Machine Learning Engineer at Defog, working on model-finetuning and dataset curation. Before joining Defog, Wendy spent most of the last decade as a copywriter, where she helped build some of the world’s biggest brands.
← More blogs